
Tabelle pivot
Lobiettivo di questa pagina è quello di descrivere le funzionalità e le potenzialità delle tabelle pivot in Excel.
Lo scopo prevalente dell'uso della tabella pivot è quello di trasformare una tabella, spesso costituita da un lungo elenco di campi e record in una forma più semplice, poche righe e poche colonne.
Consultare una tabella costituita da molteplici campi e da innumerevoli record allo scopo di ottenere valutazioni complessive può essere un compito particolarmente gravoso da affrontare senza le opportune tecniche e gli appropriati strumenti.
La tabella pivot è uno strumento fra questi; essa è una funzionalità di Excel che consente di ottenere sintesi globali, di ridurre i tempi per l'analisi dei dati e di evidenziare tendenze, permettendo in tal modo di assumere decisioni in modo più rapido e sicuro.
Una tabella pivot trasforma una tabella in un'altra, generalmente più piccola costituita da poche colonne e poche righe, in grado di mostrare un particolare riassunto delle informazioni contenute nella tabella di partenza.
Le tabelle pivot consentono dunque di organizzare, suddividere in categorie e presentare i dati sotto forma di riepiloghi in modo da attribuire un significato ad una qualsivoglia mole di dati.
Schematicamente si usano le tabelle pivot per
• raggruppare i dati di una variabile;
• raggruppare i dati di due variabili congiuntamente;
• incrociare i dati di due o più variabili.
Dati qualitativi e dati quantitativi
I dati possono essere classificati in due grandi categorie
• Dati qualitativi: vengono espressi in termini di categorie nominali oppure ordinali.
• Dati quantitativi : vengono espressi in forma numerica sia discreta che continua.
Sono qualitativi i dati espressi per mezzo di attributi o categorie che possono o meno essere disposti in un ordine prefissato. Ad esempio la provincia di nascita, il colore dei capelli di una persona, la marca di una automobile sono esempi di categorie le cui modalità sono prive di un ordine prefissato.
Le caratteristiche distinte senza un ordine implicito prendono il nome di categorie nominali e, con qualsiasi strumento vengano analizzate risultano piuttosto deboli dal punto di vista del trattamento statistico, poiché è difficile esprimere differenze relazionali (minore:< maggiore:> ) tra una categoria e l'altra. Non esiste in altre parole nessun' altra relazione tra gli attributi che quella di uguale/diverso.
Se una caratteristica si presenta solo con due modalità (si/no, maschio/femmina, 0/1, sposato/non sposato) si usa chiamarle col termine di variabili dicotomiche o binarie; esse godono di alcune proprietà un pò più ampie di quelle nominali e il loro trattamento statistico è sicuramente più efficace.
Al contrario, le categorie di un albergo indicate dal numero di stelle(***, **** etc..) il livello di soddisfazione del cliente (non sufficiente, sufficiente, buono, discreto, ottimo) o titolo di studio (elementare, media, diploma, laurea) sono categorie che possiedono un ordine naturale.
Questi tipi di caratteristiche sono dette ordinali e si possono disporre in una relazione d'ordine di tipo (relazionale) maggiore/minore .
Indicando quale categoria è più grande, migliore o preferita, ma non di
quanto è più grande, migliore o preferita.
Nel campo opposto, i dati quantitativi, possono essere espressi in termini numerici discreti, sono cioè formati solo da numeri naturali come 0, 1, 2, 3, 4 etc.. quando derivano da un procedimento di conteggio o enumerazione.
Il numero di componenti di un nucleo familiare, il numero di corridori partecipanti ad una gara o il numero dei globuli rossi per mm3 di sangue sono tutti esempi di conteggio che hanno come risposta un numero intero maggiore o uguale a zero.
Saper riconoscere queste differenze è piuttosto importante nelle applicazioni informatiche. Excel, in particolare, contraddistingue subito queste categorie, imbandierando i dati qualitativi sulla sinistra della cella di immissione come stringhe alfanumeriche. Mentre i dati quantitativi, cioè i numeri, vengono da subito imbandierati a destra.
Creazione di una tabella pivot
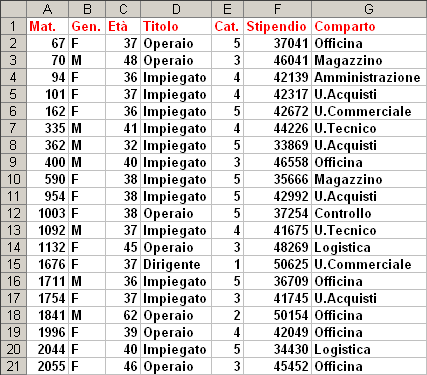
Apriamo il file p1.xls che dovrebbe essere costituito da un unico foglio che dovrebbe appparire come segue
Selezionare la scheda inserisci e fare clic sull'icona Tabella pivot.

Se il cursore di selezione è posizionato all'interno dell'area dati, essa verrà automaticamente selezionata. Prima di dare il comando di creazione di una tabella pivot occorre selezionare una qualsiasi cella della tabella. In questo modo Excel considererà come tabella tutte le righe e colonne piene che circondano la cella selezionata, fino alla prima riga o colonna vuota.

indichiamo poi la locazione dell'attuale foglio di lavoro dove impostare la nuova tabella pivot; a questo punto dovrebbe apparire la seguente scheda:
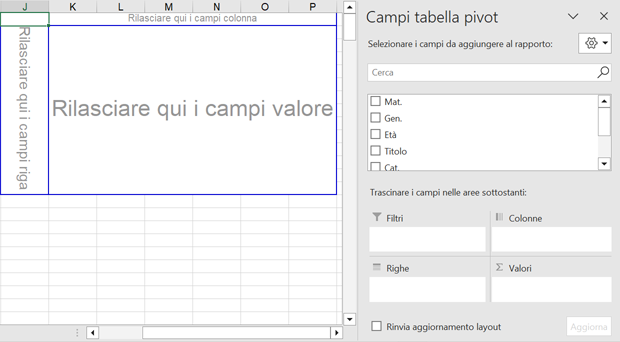
La scheda con le opzioni mostrate, serve a collocare i campi della tabella nelle righe e nelle colonne e a definire quali operazioni di conteggio, somma o media si vuole inserire nelle singole celle.
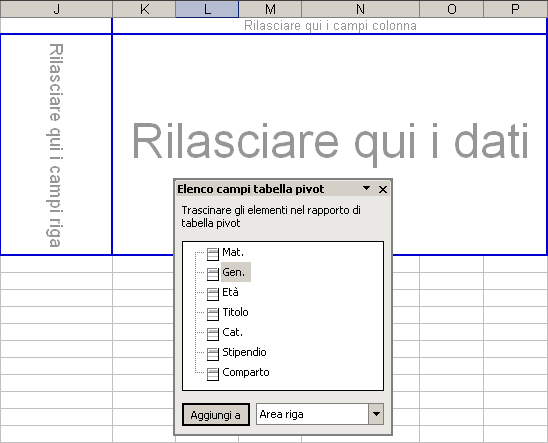
Facciamo attenzione alla finestra che contiene l'elenco dei campi come appaiono nelle intestazioni di colonna e lo schema vuoto della tabella con righe, colonne e celle centrali.
Facendo clic e tenendo premuto il tasto del mouse su uno dei nomi dei campi
si può trascinare l'etichetta nello schema vuoto per collocarlo sull'area
RIGA o COLONNA o sulla parte centrale denominata DATI.
In questo caso :
1 Facciamo clic su Gen. e trasciniamo l'etichetta nell'area RIGA.
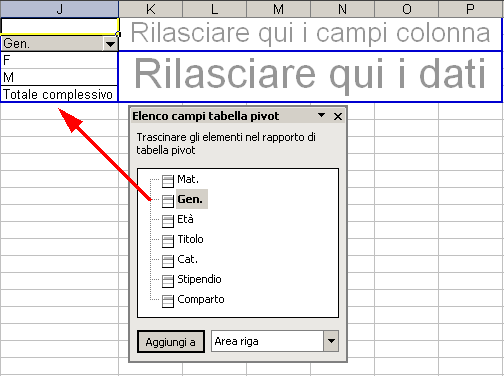
2 Facciamo clic su Titolo e trasciniamo l'etichetta nell'area COLONNA.

3 Facciamo di nuovo clic su Gen. e trasciniamo l'etichetta nell'area DATI.

L'area DATI contiene ora il conteggio dei maschi e delle femmine presenti nell'elenco di partenza. Se nell'area dati fosse stato collocato il campo Stipendio o il campo Cat. essendo questi dei numeri avrebbe calcolato la somma dello stipendio al posto del conteggio.
La tabella pivot contiene sei celle di dati, più una riga in basso e una colonna a destra con i totali rispettivamente di riga e di colonna. I nomi dei due campi appaiono come munù a comparsa; infatti facendo clic su di essi compaiono le modalità qui sotto illustrate per titolo di mansione.
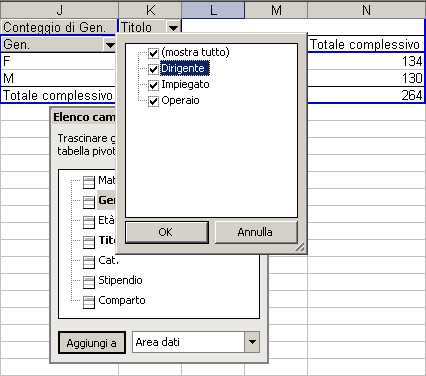
Ogni modalità è preceduta da un segno di spunta . perciò facendo clic su di essa la colonna corrispondente nella tabella viene rimossa, aggiornando di conseguenza i totali di riga e di colonna.
In questo modo si possono visualizzare solo le modalità desiderate , magari eliminando colonne o righe con pochi elementi o con elementi che non rietrano nel campo di analisi. Se si desidera , per esempio visualizzare solo soggetti femminili che fanno i dirigenti o gli impiegati, basta deselezionare la casella M nel menù a tendina Gen. e il risultato dovrebbe essere come qui di seguito illustrato.
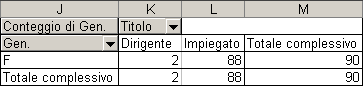
Si può osservare facilmente il calcolo dei nuovi totali di riga e di colonna che contengono ora conto soltanto del sottoinsieme degli elementi selezionati.
Dobbiamo osservare che la struttura della tabella pivot è estremamente
flessibile.
Se trasciniamo l'etichetta Titolo, presente nell'area COLONNA sulla sua
posizione originale nella sche dell'elenco campi .
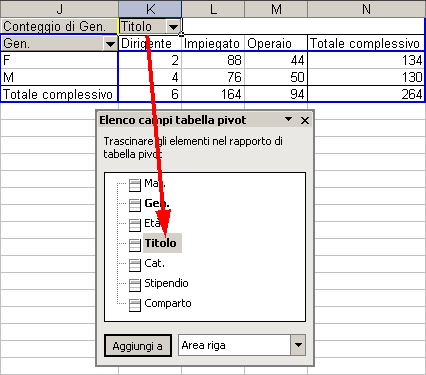
Otteniamo, come risultato quello di rimuovere il campo Titolo dall'area COLONNA. Possiamo fare la stessa cosa col campo Gen.

In tal modo abbiamo resettato sia le righe che le colonne. Ora trasciniamo l'etichetta Comparto dalla sceda dei campi nell'area RIGA.

otteniamo questo primo risultato:
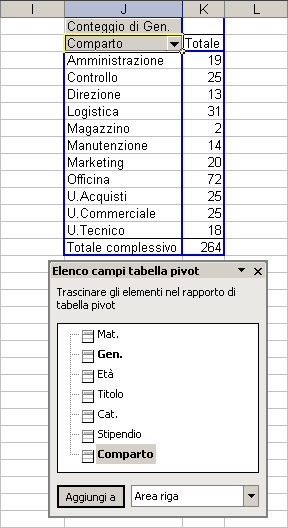
Trasciniamo poi il campo Gen. nell'area Colonna
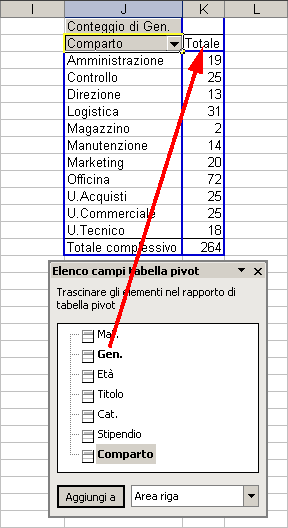
otterremo una tabella pivot totalmente rimaneggiata rispetto a quella iniziale.

dove possiamo osservare la distribuzione dei due generi M ed F nei vari comparti aziendali.
Ipotizziamo che una volta costruita la tabella pivot iniziale volessimo rifarla con altri criteri, basterebbe trascinare le etichette Titolo, Gen. e conteggio di Gen. nella scheda contenente l'elenco dei campi,

andando a ricostituire la tabella vuota iniziale .
Immaginiamo invece di voler rappresentare la media degli stipendi in base al genere (M/F).

Trasciniamo dalla scheda dell'elenco campi il campo stipendio all'incrocio della zona RIGA e COLONNA. Il risultato sarà il seguente:
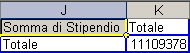
Selezioniamo l'etichetta Somma di stipendio nella tabella pivot e facciamo clic sul pulsante destro del mouse; scegliendo poi la voce "Impostazioni Campo" accessibile anche attraverso il menù ad icone. Dovrebbe essere visibile la seguente finestra:

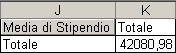
Dove noi sceglieremo l'operatore media, richiedendo, dunque, una media
degli stipendi.
Otteniamo , in prima battuta, una media degli stipendi della popolazione
del nostro elenco originario.
Trasciniamo ora l'etichetta Comparto nella scheda dell'elenco campi nella zona RIGA.
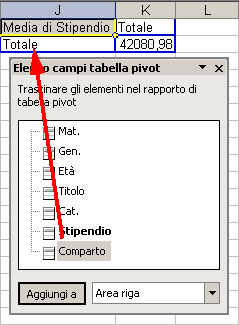
Come si poteva pensare, otteniamo delle medie di stipendio riferite ai singoli comparti.

L'operazione di media è resa possibile perché lo stipendio è un dato quantitativo, numerico, assoggettabile ad operazioni aritmetiche e ponderali. Trasciniamo ora il campo Gen. nella zona COLONNA.

Otterremo il seguente risultato:

un prospetto riassuntivo delle medie degli stipendi riferiti sia ai comparti aziendale che al genere (M/F).
Analisi dei dati
Come si può intuire una analisi dei dati può essere eseguita in differenti modi, riprendiamo il caso della tabella contenuta in dischi.xls : che abbiamo preso come esempio perché è una base di dati molto esigua quindi facilmente maneggevole in quanto snella.
Questa tabella è stata già analizzata coi filtri e coi subtotali, ma esistono ulteriori strumenti per estrapolare tendenze e per ottenere sintesi. Uno di questi è la formattazione condizionale.
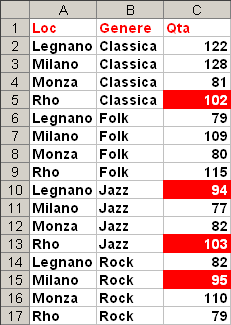
Supponiamo di voler evidenziare le celle del campo Qta che hanno un valore compreso tra 90 e 105; selezioniamo l'area di dati di nostro interesse; e scegliamo dal menu Formato>Formattazione condizionale.

Dopo aver fissato l'intervallo dei valori della condizione logica, applichiamo uno sfondo rosso e un colore di primo piano bianco per le celle che soddisfano la condizione ottenendo il seguente risultato:
Ovviamente anche da questo tipo di database è possibile ottenere una sintesi
usando il metodo delle tabelle pivot.
Inseriamo la tabella pivot in cella F1

trasciniamo Il campo Loc nell'area RIGA.
Il campo Genere nell'area COLONNA.
Il campo Qta nell'area DATI.
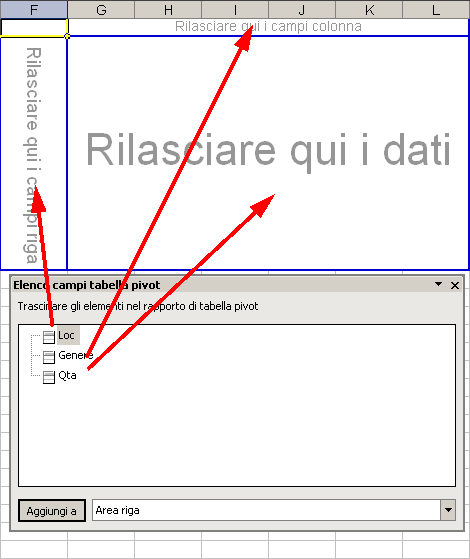
Il risultato ottenuto sarà il seguente:
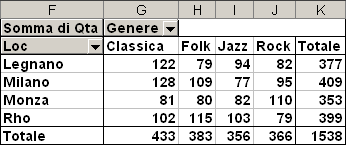
Copiando la tabella generata e reincollando solo i valori in un altro foglio o cartella otteniamo una tabella a campi incrociati decisamente più compatta rispetto a quella originale.