
Linguaggio assembly 8086
Per programmare un microprocessore si usa un linguaggio simbolico chiamato linguaggio assembly (o assembler), costituito da istruzioni che rappresentano il funzionamento interno del processore e delle sue operazioni elementari.
Si dice che l'assembly è un linguaggio orientato alla macchina, perché non si può scrivere software in assembly se non si conosce l'architettura del microprocessore che si vuole programmare. Questo significa che esistono molteplici assembly, a secondo del microprocessore che si vuole programmare, anche se tutti gli assembly hanno come denominatore comune le caratteristiche enumerate nella pagina sui linguaggi macchina.
Per tradurre un programma sorgente scritto in assembly x86,si usa un programma assemblatore, che accetta istruzioni assembly mnemoniche e li traduce automaticamente in codice oggetto.L'assemblatore assegna,quindi,all'istruzione scritta il modo sintatticamente corretto il rispettivo codice macchina.L'assemblatore viene anche detto traduttore 1:1.,perché ad un'istruzione in assembly corrisponde un'istruzione in linguaggio macchina.
A questo proposito, bisogna dire che al suo interno, un elaboratore, memorizza dati ed istruzioni, codificandoli in esadecimale; questo per ovvi motivi:
(14)10=(1110)2=(E)16
come si vede, per codificare ad es. il numero 14 ci vogliono due cifre decimali, quattro cifre binarie e soltanto una cifra esadecimale; una informazione in codice esadecimale è meno ingombrante da rappresentare. Il computer memorizza in esadecimale non solo i dati ma anche le operazioni come l'addizione, la sottrazione o il salto tra due istruzioni; diventa dunque comodo associare dei codici mnemonici (facili da ricordare) alle operazioni usate per programmare la macchina.
| Operazione | Codice | Termine mnemonico |
| Addizione | 30H | ADD |
| Sottrazione | 31H | SUB |
| Salto a | 40H | JMP |
L'assembly,come tutti i linguaggi,possiede una grammatica che consente di costruire frasi(istruzioni)in accordo ad una sintassi,un'insieme di istruzioni,dirette al microprocessore,e un'insieme di pseudo-istruzioni o direttive,che sono i comandi diretti all'assemblatore.
Implementa inoltre un paradigma di programmazione di tipo imperativo o
procedurale secondo il teorema di Jacopini-Bohm che afferma:
per codificare una qualsiasi procedura sono
necessarie 3 strutture di controllo,la sequenza,la selezione e l'iterazione.
(l'informatica è tutta qui)
Il modello generale di un'istruzione in assembly è il seguente:
[etichetta [:]] COP [Destinazione [, Sorgente] ] [;Commento]
come si vede dalla sistassi l'unica istruzione obbligatoria è il codice operativo (COP) tutti gli argomenti restanti sono opzionali (dato che sono contenuti in parentesi quadre).
L'etichetta è opzionale, serve solo a ad associare un nome simbolico ad una variabile o all'indirizzo di una istruzione del programma. Bisogna tener conto che l'etichetta può essere accompagnata dal carattere ":" che è obbligatorio nel caso che l'etichetta indichi l'indirizzo di una istruzione, mentre non si mette quando l'etichetta indica identifica una locazione di memoria assegnata ad una variabile.
Il COP può avere al massimo due operandi (destinazione, sorgente).
Anche la presenza di eventuali commenti preceduti dal punto e virgola non
sono obbligatori anche se consigliati.
Istruzioni per il processore 8086
Il set di istruzioni per l'assembly x86 può essere classificato per categoria
| Istruzioni di uso generale | |
| MOV | Sposta i dati dalla memoria al processore e viceversa |
| NOP | Indica che non bisogna eseguire alcuna operazione |
| PUSH | Inserisce un dato nello stack |
| POP | Preleva un dato dallo stack |
| XCHG | Scambia il contenuto di due registri oppure di un registro e di una locazione di memoria, oppure un registro ed il contenuto di una locazione di memoria. Le dimensioni degli argomenti devono essere le stesse. |
| Istruzioni per l'input/output | |
| IN | Legge il valore da un porto |
| OUT | Scrive un dato su un porto |
| addizione | |
| ADD | Addizione |
| ADC | Addizione con carry |
| DAA | Addizione con aggiustamento decimale nel caso gli operandi siano in codice BCD |
| INC | incremento |
| Sottrazione | |
| SUB | Sottrazione |
| SBB | Sottrazione con prestito |
| CMP | Confronto |
| NEG | Negazione (complemento a 2) |
| DEC | Decremento |
| DAS | Aggiustamento decimale nel caso gli operandi siano in codice BCD |
| Moltiplicazione | |
| MUL | Moltiplicazione |
| IMUL | Moltiplicazione con numeri interi |
| Divisione | |
| DIV | Divisione con numeri naturali |
| IDIV | Divisione con numeri interi |
| CBW | Conversione di byte in parola (word) |
| CWD | Conversione di word in doppia word |
| Istruzioni per operazioni logiche | |
| AND | And logico |
| NOT | Not logico o complemento a 1 |
| OR | Or logico o inclusivo |
| TEST | Confronto logico |
| XOR | Or esclusivo |
| Istruzioni per operazioni di shift e rotazione | |
| RCL | Rotazione a sinistra con carry |
| RCR | Rotazione a destra con carry |
| ROL | Per la rotazione a sinistra |
| ROR | Per la rotazione a destra |
| SAL | Shift aritmetico a sinistra |
| SAR | Shift aritmetico a destra |
| SHL | Shift logico a sinistra |
| SHR | Shift logico a destra |
| Istruzioni per le operazioni sui flag | |
| CLC | Azzera i flag di carry |
| CLD | Azzera i flag di direzione |
| CLI | Azzera i flag di interrupt |
| CMC | Complemento del flag di carry |
| STC | Setta il flag di carry |
| STD | Setta i flag di direzione |
| STI | Setta i flag di interrupt |
| Istruzioni per le operazioni di controllo dei trasferimenti | |
| CALL | Chiamata ad una procedura |
| JMP | Salto |
| RET | Ritorno da una procedura |
Nei controlli con trasferimento condizionato, lesecuzione del salto è determinato dal risultato di precedenti istruzioni di confronto oppure dal valore attuale dei registri di flag.
| Trasferimenti condizionati | |
| JA | Salta se maggiore nel caso di numeri naturali |
| JAE | Salta se maggiore o uguale con numeri naturali |
| JB | Salta se minore nel caso di numeri naturali |
| JBE | Salta se minore o uguale nel caso di numeri naturali |
| JC | Salta se il carry è settato |
| JCXZ | Salta se il registro CX è uguale a zero |
| JE | Salta se gli operandi sono uguali |
| JG | Salta se maggiore con i numeri interi |
| JGE | Salta se maggiore o uguale con i numeri interi |
| JL | Salta se minore con i numeri interi |
| JLE | Salta se minore o uguale con i numeri interi |
| JNC | Salta se i carry è resettato |
| JNE | Salta se diverso |
| JNO | Salta se non cè overflow |
| JNS | Salta se il segno è positivo |
| JO | Salta se cè overflow |
| JS | Salta se il segno è negativo |
| JPE | Salta se la parità è pari |
| JPO | Salta se la parità è dispari |
| Istruzioni per il controllo dei cicli | |
| LOOP | Esegue un ciclo |
| LOOPNE | Esegue un ciclo se uguale |
| LOOPNE | Esegue un ciclo se non è uguale |
Modi di indirizzamento
I modi di indirizzamento usati per i microprocessori della classe x86 sono:
1 Indirizzamento immediato
L'istruzione contiene il valore per cui il sorgente è un valore costante. Ad es.
ADD AL,7
significa addizionare 7 al valore del registro AL
CMP BL, 55
confronta il contenuto del registro BL con 55.
La costanti possono essere essere espresse in una delle seguenti quattro basi: decimale, binario, ottale ed esadecimale.
Se si vuole esprimere una costante in una base diversa dalla base 10, basta aggiungere alla costante
● il suffisso B se la base è binaria, ad
es. 1101B
● O se la base è ottale ad es. 232O
● H se la costante è esadecimale, ad esempio
7FH
2 Indirizzamento con registro
In questo caso gli operandi sono contenuti in specifici registri e, nel caso dei registri accumulatori, possiamo usare sia la lunghezza word (16bit) che la lunghezza byte (8bit) chiaramente sia l'operando sorgente che l'operando destinazione devonop avere la stessa dimensione. Ad es.
MOV AX, BX
ADD DL, AL
CMP AX, DX
con l'istruzione MOV CX,BH che è sbagliata perché i due registri non hanno la stessa dimensione.
3 Indirizzamento diretto (o assoluto)
Uno dei due operandi si trova nel segmento dato ed identificato da un etichetta. Per esempio:
MOV AX, pippo
MOV pluto, AL
MOV pippo, 5
L' istruzione MOV 5, AL è' errata, perché l' operando di destinazione non può essere una costante; anche l' istruzione
MOV marco, andrea
è errata perché i due operandi non possono essere entrambi locazione di memoria.
4 Indirizzamento indiretto
L' operando si trova ad un indirizzo puntato dai registri base o indice quali: BP, BX, SI, BI Per esempio nell' istruzione
MOV CX, [DI]
Se non si vuole utilizzare la regola di default, occore esplicitare anche il segmento (regola del segment override). Per esempio nell' istruzione
MOV AX, DS: [BP]
Il contenuto del registro BP viene sommato al contenuto del registro del
segmento DS, anziché a SS come imporrebbe il default.
Quando si usa questo metodo di indirizzamento, nel caso in cui non si possa
ricavare dall' istruzione le dimensioni dell' operando, si verifca una situazione
di errore.
Per esempio, nell' istruzione INC [SI] non si può
ricavare dall'istruzione stessa la dimensione della locazione di memoria
che deve essere incrementata; lo stesso problema si ha con l' istruzione
MOV [BX], 5.
Per risolvere il problema occorre comunicare al processo un informazione
aggiuntiva, nel seguente modo:
INC word ptr [SI] se la variabile ha dimensione word, oppure
MOV byte ptr [BX], 5 se la variabile puntata ha dimensione byte.
Altri prefissi sono dword ptr se si punta alla doppia
word , oppure qword ptr se si punta alla quadrupla
word.
Quindi quando non si può ricavare dall' istruzione la dimensione degli operandi,
questa deve essere esplicita.
Una variante al metodo precedente consiste nell' aggiungere o togliere un
valore costante. Per esempio
MOV AX [SI + 5] oppure MOV, [DI - 2]
al valore contenuto nel registro viene aggiunto o tolto il valore costante indicato, prima di addizionarlo al segmento moltiplicato per 16.
5 Indirizzamento indicizzato
Nell' indirizzamento indicizzato vengono usati i registri SI e DI. In questo caso il registro rappresenta l' offset. Per esempio, nell' istruzione
MOV AX, T [SI]
La variabile T deve essere immaginata come un array ed è la base del blocco di partenza, mentre SI è l'offset.
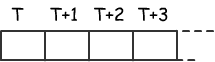
Se SI contiene il valore 2, viene referenziata la locazione etichettata
con T + 2.
Anche in questo caso valgono le regole indicate nel punto precedente, con
la possibilità di aggiungere o togliere un valore costante al contenuto
del registro.
6 Indirizzamento con base ed indice
In questo tipo di indirizzamento l'indirizzo richiesto viene indicato tramite un registro (BX o BP) un registro indice (SI o DI) ed uno spiazzamento opzionale, come ad es.
MOV [AX,[BX+SI+costante]]
Modelli di memoria
Nei sistemi Intel, non è consentito all'utente di decidere in quale zona di memoria allocare il programma, in essi, la gestione della memoria segmentata l'utente decide il numero ed il tipo di segmenti da usare, l'utente stesso, deve esplicitamente richiedere la memoria al modulo che effettua il linking, indicando il modello di memoria da usare. I modelli di memoria consentiti sono.
.TINY L'utente deve organizzare il programma mettendo in un unico segmento sia i dati sia il codice: di conseguenza, la dimensione massima di un programma è uguale alla massima dimensione di un segmento, cioè 64K. Questo è l'unico modello di memoria che consente di creare i file con estensione .com.
.SMALL L'utente deve organizzare il programma utilizzando due segmenti: uno per il codice e uno per i dati.
.COMPACT Il programma è organizzato con un segmento per il codice e più segmenti per i dati.
.MEDIUM Il programma è organizzato con un solo segmento per i dati e più segmenti per il codice.
.LARGE Il programma è organizzato con più segmenti per i dati e più segmenti per il codice, ma non è consentito definire variabili che abbiano una dimensione pari a 64K
.HUGE Il programma è organizzato con più segmenti per i dati e più segmenti per il codice ed è consentito definire variabili che abbiano una dimensione pari a 64K.
Per quelle che sono le nostre esigenze, in tutti i programmi che seguono utilizzeremo il modello .SMALL. La truttura del nostro programma assembler 8086 avrà di solito il seguente schema

Tutti i programmi sono stati testati con il compilatore tasm. allegato in questo file zip. Quasi sempre ricorrono le seguenti direttive:
.STACK [dimensione]
Questa direttiva definisce il segmento di stack, indicando al posto dell'argomento
"dimensione" un numero che rappresenta la quantità desiderata, espressa
in byte; la massima dimensione nei sistemi MS_DOS è 64K. Il valore della
dimensione viene specificato ad esempio come
.STACK 100H
che richiede uno stack segment di 256 locazioni (100 in esadecimale). Si
tratta di una direttiva non obbligatoria ma è opportuno che ci sia soprattutto
quando si usano le istruzioni che utilizzano il segmento di stack (PUSH,POP,
indirizzamenti indicizzati o indiretti che usano il registro BP)
.DATA
Questa direttiva definisce il primo segmento per i dati . La dimensione
è calcolata automaticamente come totale dello spazio usato da tutte le variabili.
.CODE
La direttiva .CODE definisce il primo segmento per il codice eseguibile.
La dimensione viene calcolata automaticamente come totale dello spazio usato
dalle singole istruzioni.
Solitamente (di default) non si impone di indicare nelle istruzioni gli
indirizzi in modo completo Segmento:Offset, ma solamente l'offset, occorre
a tal proposito inizializzare il registro DS con l'indirizzo di partenza
assegnato al segmento dati.
Questo valore è deciso dal sistema al momento del caricamento e viene messo
nella variabile d'ambiente @DATA. Poiché non è possibile passare direttamente
il contenuto della variabile @DATA al registro DS (in quanto non è disponibile
l'istruzione per fare questo), occorre usare un altro registro di appoggio
per il quale questa assegnazione è possibile, normalmente il registro AX
tramite la seguente coppia di istruzioni.
MOV AX,@DATA
MOV DS,AX
Le due istruzioni suddette servono per inizializzare correttamente il registro
di segmento DS, in modo da usare nel codice, come indirizzi, solo gli offset.
Per terminare il programma, useremo invece le due seguenti istruzioni
MOV AX,4C00H
INT 21H
L'effetto della prima istruzione è quello di mettere la costante esadecimale
4C nel registro AH e la costante 00 in AL. La secona istruzione INT 21H
richiede uno dei servizi del DOS: il 4C (in ogni chiamata al DOS il numero
del servizio neve essere contenuto in AH) perché è quello che restituisce
il controllo al sistema operativo. In AL viene messo il codice di errore:
il valore zero indica che tutto si è svolto correttamente.
Seguirà la pseudo-istruzione END che rappresenta
la fine fisica del programma ; comanda, infatti all'assemblatore di terminare
la fase di assemblaggio.
TITLE X
.model small
.stack
.data messaggio db "Ciao a tutti sto imparando l'assembly","$"
.code
mov ax,@DATA
mov ds,ax
mov ah,09
lea dx,messaggio
int 21h
mov ax,4c00h
int 21h
end
viene messo il valore 9 nel registro AX che predispone il processore alla
stampa a video di una stringa.
La stringa da stampare viene posta nel registro DX attraverso l'istruzione
LEA DX,MESSAGGIO
L'interrupt 21H si occupa di attuare l'operazione di stampa. Come si vede,
l'assembly, al contrario di certi linguaggi ad alto livello, non è
case-sensitive, cioè, è indifferente alle maiuscole/minuscole.
Importante è invece l'operazione di concatenamento della stringa
in output con il carattere $ indicatore della terminazione
della stringa stessa.
Dopo aver salvato il codice in un file di testo con nome ed estensione x.asm
nella cartella TASM dove sono contenuti il files del compilatore, assemblare
il programma dalla riga di comando con
C:\TASM>tasm x
linkare il programma col comando:
C:\TASM>tlink x
eseguire il programma digitando:
C:\TASM>x
Se invece di una intera stringa vogliamo stampare a video un singolo carattere,
occorrerà usare il metodo illustrato nel seguente programma
TITLE Y
.model small
.stack
.data
.code
mov ax,@DATA
mov ds,ax
mov dl,66
mov ah,02
int 21h
mov ax,4c00h
int 21h
end
Per stampare a video il contenuto di un registro basta inserire il contenuto
da stampare nel registro DL , settare a 2 il valore di AH e invocare l'interruzione
21.
MOV AH,2
MOV DL,66
INT 21H
In questo caso viene stampato a video il carattere 'B', che corrisponde
al 66° elemento del codice ASCII.
Ogni registro ha due parti, ad esempio, AX ha una parte bassa AL e una parte
alta AH. Sia AL che AH sono costituiti da 8 bit e possono dunque computare
fino a 256=28 .
Editare e salvare il seguente file col nome y.asm.
C:\TASM>tasm y
linkare il programma col comando:
C:\TASM>tlink y
eseguire il programma digitando:
C:\TASM>y
Se invece di stampare un carattere, vogliamo stampare un numero (una cifra)
possiamo usare l'accorgimento che si vede nel seguente programma
TITLE Z
.model small
.stack
.data
op db 3
.code
mov ax,@DATA
mov ds,ax
mov dl,op
add dl,48
mov ah,02
int 21h
mov ax,4c00h
int 21h
end
L'operando op=3 viene messo nel registro DL; allo stesso registro viene
poi aggiunto 48 (48 è il codice ASCII che rappresenta lo 0 a cui
seguono gli altri numeri fino al 9). In questo modo, il programma, invece
di stampare il 3° carattere del codice ASCII stamperà il 3. Possiamo
poi compilare e linkare il programma scritto come visto negli esempi precedenti.
Compilatore
Come abbiamo visto, per sviluppare programmi scritti in codice assembler sono necessari alcuni strumenti software essenziali: l'editor di testo, il programma assemblatore, il linker.
L'editor di testi o text editor è un programma che permette di scrivere un documento costituito esclusivamente da testo; l'editor di testi più comunemente usato per programmare sui sistemi Windows è il blocco note (Noteblock). Alla fine della scrittura del codice sorgente in linguaggio assembler il documento realizzato deve essere salvato con estensione .asm. Nel programma sorgente ogni carattere viene codificato nel codice macchina secondo il set di caratteri ASCII.
Come assemblatore può essere usato tipicamente MASM (Microsoft Macro Assembler) oppure, come usiamo noi, il TASM (Turbo Assembler) .L'assemblatore è' un programma di traduzione di procedure scritte in linguaggio assembly : esso assegna alle frasi sintatticamente corretto il rispettivo codice macchina.l'input al programma è costituito dalla procedura dell'utente scritta in linguaggio assemblativo (sorgente)con l'impiego di un editor di testo e memorizzato sul disco in un file .asm.
Il programma assemblatore traduce sia i dati che le istruzioni del programma sorgente come un unico insieme di dati,detto data set di input,e fornisce in uscita il data set di output scritto in codice oggetto. Fisicamente,ad una lista di byte del programma sorgente corrisponde in uscita dal programma assemblatore, una diversa lista di byte del programma oggetto (File.obj).
L'assemblatore, fa uso di una variabile chiamata termine location
counter utilizzata per determinare gli indirizzi occupati dai singoli
byte del data set di output.Il valore iniziale di questo parametro di solito
è 0.
Nella prima passata il programma assemblatore genera una tabella che mette
in corrispondenza i nomi simbolici assegnati alle etichette con il valore
corrente del location counter.Questa tabella,detta symbol table,contiene
anche i valori attribuiti ai nomi simbolici posti in ciascun campo operando
delle istruzioni e definite da opportune pseudo-istruzioni.
La seconda passata si esaurisce semplicemente assegnando ai nomi simbolici
i valori ottenuti dalla symbol table.L'assemblatore deve essere in grado
di fornire messaggi di errore nel caso non venga rispettata la sintassi.
In generale se un programma non ha errori di sintassi non significa necessariamente
che "giri",ma semplicemente che la sintassi è corretta.
Linker
L'assemblatore generalmente traduce il programma sorgente calcolando gli
indirizzi a partire dall'indirizzo 0. Il programma oggetto può quindi essere
eseguito correttamente solo se viene allocato in memoria a partire proprio
dalla locazione di indirizzo 0.
Questo in genere non è possibile in quanto le prime locazioni vengono utilizzate
dal sistema operativo stesso e il programma utente è allocato in memoria
centrale solo a partire da un altro indirizzo. Indichiamo con IBR l'indirizzo
della locazione di memoria a partire dalla quale il programma è allocato
in memoria per la sua esecuzione.Affinchè il programma possa essere eseguito
correttamente tutti gli indirizzi che compaiono all'interno del programma
oggetto devono essere incrementati della quantità IBR.
L'indirizzo IBR si chiama indirizzo base di rilocazione.Queste operazioni
di rcalcolo sugli indirizzi sono svolte dal programma linker(collegatore).Oltre
a questo il linker costruisce un programma unico a partire dai programmi
oggetto separati (che possono essere procedure esterne e librerie)prodotti
dall'assemblatore,completando, con l'aiuto delle informazioni che si trovano
nel programma sorgente stesso,i riferimenti che erano rimasti in sospeso.Esso
giustappone il programma, le eventuali routine esterne e le librerie una
di seguito all'altro;inoltre,dove necessario, trasforma gli indirizzi in
modo da tenere conto di questo concatenamento.