
Allocazione dinamica in C
In un programma scritto in C, si hanno a disposizione due modi fondamentali
per usare la memoria contenente i dati. Il primo consiste nelluso delle
variabili globali e locali.
Per le variabili globali lallocazione è fissata al momento dellesecuzione
del programma, mentre per le variabili locali lo spazio è creato tramite
lo stack, che si trova nella zona alta della memoria del sistema.

Il secondo sistema di memorizzazione dei dati avviene tramite lallocazione
dinamica del C. Secondo questo metodo, le informazioni da memorizzare sono
allocate nellarea in un'area di memoria disponibile chiamata heap che si
trova tra lo stack e lo spazio riservato al programma.
Lo stack cresce dallalto verso il basso e la sua dimensione dipende dal particolare programma
in esecuzione.
Un programma molto ricorsivo ha uno stack ampio, perchè variabili globali ed
indirizzi di ritorno sono memorizzati lì.
La memoria occupata al programma e dalle variabili globali,
invece è fissa per tutto il tempo di esecuzione del programma.
La memoria necessaria per far fronte ad una richiesta di allocazione dinamica viene ricavata nell'
area della memoria libera (cioè nello heap); può accadere così che la memoria libera si esaurisca.
Le funzioni malloc() e free()
rappresentano il nucleo del sistema di allocazione del linguaggio C; esse
operano insieme usando larea di memoria libera al fine di stabilire e mantenere
una mappa della memoria disponibile.
La funzione malloc() alloca la memoria, mentre free()
la libera.
I programmi che usano queste funzioni dovrebbero comprendere il file di
intestazione stdlib.h. Il prototipo della funzione
malloc() è il seguente:
void *malloc(int numero_di_byte);
restituisce un puntatore i tipo void, che significa che può essere assegnato
a qualsiasi tipo di puntatore.
Se la chiamata ha esito positivo, malloc() restituisce
un puntatotre al primo byte dell'area di memoria disponibile.
Se la memoria disponibile non è sufficiente per soddisfare la richiesta
di malloc() la stessa restituisce un valore NULL.
Per determinare il numero preciso di byte necessari ad ogni tipo di dati
si ricorre alla funzione sizeof(). La funzione
free() rappresenta il contrario di malloc()
perchè restituisce al sistema memoria allocata in precedenza. Una volta
liberata la memoria, essa può essere riusata da una nuova chiamata malloc().
Il prototipo della funzione free() è il seguente:
void free(void *p);
L'unica cosa da ricordare è di chiamare free() solo con un argomento valido perchè, in caso contrario, si distruggerebbe la mappa della memoria libera.
Nel caso del C++ abbiamo già visto come la richiesta di memoria al sistema venga effettuata dall'operatore new tramite la sintassi
puntatore_var=new tipo_var;
anche in questo caso esiste un operatore opposto adibito al rilascio della memoria non più usata da una variabile puntatore: l'operatore delete.
delete puntatore_var;
Al pari di malloc() new restituisce un puntatore
a NULL se l'allocazione richiesta non ha successo.
Di conseguenza, è opportuno controllare sempre il puntatore prodotto da
new prima di usarlo.
Analogamente a malloc, new
alloca memoria dall'heap, per questo motivo delete
può essere usato solo con un puntatore alla memoria allocata da new.
L'uso di delete con un qualsiasi altro tipo di indirizzo
dà origine a seri problemi.
Rispetto a malloc(), new comporta
numerosi vantaggi: calcola automaticamente la dimensione del tipo da allocare.
Con new non è necessario usare l'operatore sizeof,
questo impedisce l'allocazione accidentale di una errata quantità di memoria.
L'utilizzo di new è gia stato visto quando abbiamo
tentato di costruire delle semplici
liste a puntatori in C++.
In C standard, la struttura di questi listati resta sostanzialmente invariata;
come detto bisogna usare malloc() invece di new
con la precauzione di inserire la standard library stdlib.h;
mentre le operazioni di output vengono eseguite con printf
e quelle di input con l'istruzione scanf della libreria
stdio.h .
Per riassumere questa compatibilità riscriviamo l'esercizio
9 sulle liste concatenate in C++ nella sua equivalente versione C con
qualche piccola variazione come ad esempio le istruzioni fflush() per svuotare velocemente i buffer di input e di output.
(cliccare prima su Interactive mode :ON e poi
cliccare su Execute)
Bisogna riconoscere che ormai c'è una enorme differenza (specialmente nelle funzioni di libreria) tra C++ e il C degli albori di cinquant'anni fa, ma per le cose elementari che facciamo noi questa differenza rimane piuttosto limitata.
Chiamiamo j il puntatore al primo elemento della lista; per nostra comodità assumiamo che quando il campo j->x=0 la lista sia vuota; j punterà, dunque, al primo elemento per tutta la durata del programma. La funzione per l'inserimento di ulteriori elementi è
T *push(T *j,T *q);
ad essa viene passato il puntatore j al primo elemento
ed il puntatore q all'ultimo elemento; come si vede
dal codice, viene restituito il puntatore q all'ultimo
elemento; questo ci permette di gestire eventuali successivi inserimenti
in modo più agevole.
Non serve in questo caso restituire l'indirizzo del primo elemento perchè
la sua posizione non è cambiata rispetto al momento precedente alla chiamata
della funzione.
La funzione che si occupa di cancellare un generico elemento è
T *pop(T *j);
ad essa viene passato il puntatore al primo elemento e restituisce un puntatore sempre al primo elemento questo ci obbliga dopo il ritorno da questa chiamata di riscansionare la lista per recuperare l'ultimo elemento. Questo può essere fatto tramite due semplici istruzioni
q=j;
while(q->y!=NULL)q= q->y;
La funzione push, per inserire nuovi elementi in lista, opera secondo il seguente schema
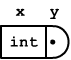
Definisco la struttura costituita da un campo x di tipo intero ed un campo y puntatore ad una struttura analoga
typedef struct t {
int x;
struct t *y;
}T;
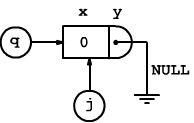
Nel main() vengono dichiarati i due puntatori j che coincide con la testa della lista e q che coincide con la coda
T *j= malloc(sizeof(T));//primo
j->x=0;j->y=NULL;//iniz.lista vuota
T *q = malloc(sizeof(T));
q=j;
Ovviamente, all'inizio, q viene fatto coincidere con j; ricordiamo che fin tanto che nel campo x del primo elemento della della lisa c'è 0, la lista viene considerata vuota.
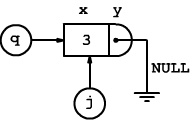
Quando viene invocata push, se la lista è vuota, il dato immesso viene semplicemente memorizzato nel primo ed unico elemento della lista
if(j->x==0 && j->y==NULL)j->x=n;
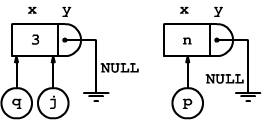
Alla seconda immissione, viene creato un nuovo puntatore p, inizialmente disgiunto da j e da q.
T *p = malloc(sizeof(T));
p->x = n;
p->y = NULL;
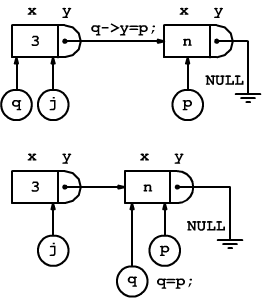
Poi in due battute il primo elemento viene collegato al secondo.
q->y=p;
q=p;
Da questo momento in poi, q punterà all'elemento in coda alla lista
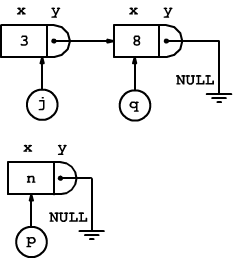
Al terzo inserimento, viene effettuata la richiesta per l'allocazione in memoria di un nuovo elemento tramite le solite istruzioni
T *p = malloc(sizeof(T));
p->x = n;
p->y = NULL;
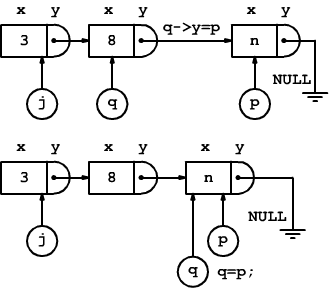
Il terzo elemento viene collegato come il precedente dalle due istruzioni
q->y=p;
q=p;
I successivi elementi inseriti saranno collegati nel medesimo modo.
L'importante è che la funzione push restituisca il puntatore di coda q,
perchè il puntatore di testa alla lista j non si
è mosso dalla sua posizione iniziale.
La funzione pop ha il compito di rimuovere un generico
elemento dalla lista, ma ci si accorge subito che essa deve essere scritta
con una certa attenzione differenziando le istruzioni a secondo che si voglia
eliminare il primo elemento di testa, l'ultimo elemento di coda o un eventuale
elemento intermedio.
In questo caso, l'importante è che ci riferiamo correttamente agli elementi
che si vogliono cancellare.
Per questo motivo, al momento della cancellazione ci viene richiesto un
indice (index) che noi consideriamo 0 per l'elemento
iniziale di testa, progressivamente crescente per quelli successivi.
![]()
inutile dire che se si cerca di puntare ad elementi esterni all'intervallo di valori dell'indice, possono succedere le cose più imprevedibili (non c'è stato tempo di aggiungere routine per l'intercettazione di errori).
Un ciclo while è in grado, in via preliminare, di contare il numero totale (n) degli elementi in lista, questo può essere comodo perchè ci permetterebbe di poter usare successivamente un ciclo for in tutta sicurezza (ma questa rimane una scelta arbitraria).
Se vogliamo cancellare il primo elemento della lista verrà eseguito il ramo if:
if(index==0){//cancello il primo elemento
if(n>1){q=j;j=j->y;free(q);}//più
elementi presenti
else {j->x=0;j->y=NULL;}//un
unico elemento presente
}
dove si nota la funzione free per liberare la memoria.
Se si vuole cancellare un elemento intermedio alla lista verrà eseguito il ramo else: posizioniamo il puntatore q (di coda) in testa alla lista e lo facciamo 'camminare' fino all'elemento precedente a quello da cancellare.
q =j;
for(i=0;i<index-1;i++) q=q->y;
Se si vuole cancellare l'elemento di coda basta, l'istruzione q->y=NULL sganciando l'ultimo elemento dalla lista
if(index==n-1){q->y=NULL;}//cancello l'ultimo elemento
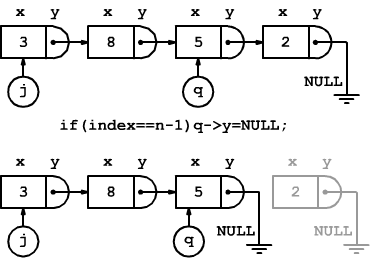
Se si vuole eliminare un elemento intermedio possiamo usare p come puntatore ausiliario all'elemento da cancellare, poi lo bypassiamo con le istruzioni

p=q->y;
q->y=p->y;
free(p);//libera memoria
in questo caso con l'istruzione free possiamo restituire
memoria al sistema.
La funzione pop restituisce il puntatore
j di testa alla lista perchè come abbiamo visto esiste l'eventualità
che sia proprio l'elemento di testa a dover essere eliminato.
Dopo la chiamata a questa funzione, il main()
conoscerà l'indirizzo del primo elemento j, ma avrà la necessità di recuperare
con sicurezza la posizione dell'ultimo elemento che come si vede avviene
attraverso le istruzioni
q=j;
while(q->y!=NULL)q= q->y;//recup.ultimo elem.
L'alternativa a questa soluzione sarebbe di far restituire alla funzione pop, un array di due puntatori, il primo corrispondente a j ed il secondo a q.
La funzione push di caricamento, può essere anche scritta in modo da restituire il puntatore di testa j.
T *push(T *j, int n){
T *q=j,*p = malloc(sizeof(T));
p->x = n;
p->y = NULL;
if(j==NULL)return p;
while(q->y!=NULL)q=q->y;
q->y=p;
return j;
}
Questa funzione ha come parametri formali in ingresso, il puntatore
j di testa ed il numero intero n.
Al suo interno viene creato il puntatore ausiliario q
al primo elemento (q=j) poi viene chiesta memoria
per allocare in nuovo elemento n in lista.
if(j==NULL)return p;
significa che j, creato precedentemente nel main,
non è stato ancora caricato di dati e la lista è vuota.
In questo caso la funzione restituisce p che punta
al primo elemento che viene inserito.
Se la condizione precedente non è verificata, significa che la lista non è vuota, quindi col ciclo
while(q->y!=NULL)q=q->y;
percorriamo la lista fino alla sua fine e con l'istruzione q->y=p;
colleghiamo l'elemento l'elemento nuovo (n).
Poi si restituisce il puntatore j alla funzione chiamante.
Se la funzione chiamante, perde j puntatore iniziale,
difficilmente possiamo recuperare i dati della lista.
Nel seguente listato per ragioni di comodità, mettiamo i numeri interi
da caricare in un vettore; possiamo anche aggiungerne o toglierne; basta
che siano separati da una virgola.
Poi usiamo la funzione precedente per inserirli in lista tramite un ciclo
for.
La lista viene successivamente stampata con print(j)
; viene tolto l'elemento con indice 3 e dopo questa modifica la lista viene
ristampata.
In questo caso, la base dei dati è costituita da un vettore di un certo numero di elementi interi chiamato V. L'istruzione
lg=sizeof(V)/sizeof(V[0]);
riesce a calcolare in automatico di quanti elementi è costituito il vettore, quindi tramite un ciclo for carichiamo la lista di tutti gli elementi inizialmente contenuti nel vettore.
L'istruzione j=pop(j,0); ci permette di cancellare l'elemento di testa
L'istruzione j=pop(j,3); ci permette di cancellare il quarto elemento partendo da sinistra.
Tramite questo programma possiamo predisporre una base di dati per poi
sottoporla al test di altre funzioni che ci interessa sviluppare.
Se poi volessimo ampliare le dimensioni della struttura, basta applicare
il precedente algoritmo ad un semplice caso pratico. Ipotizziamo di dover
scrivere un programma per la gestione di un magazzino di prodotti con il
seguente tracciato di campi

il campo id ha funzione di chiave primaria: è un codice univoco associato a ciascun elemento della lista, il campo prd è una stringa descrittiva del prodotto, il campo prz è il prezzo del corrispondente prodotto, il campo qta è la quantità di pezzi di quel prodotto presenti nel magazzino.
Per velocizzare la procedura di caricamento, l'elenco dei prodotti viene memorizzqto da programma nel vettore di stringhe S.
Viene creata un vettore della struttura di tipo REC che oltre al campo id che contiene l'indice del vettore, prevede il campo prd di tipo stringa, prelevato dal vettore S; poi, tramite un generatore random di numeri interi, i campi prz vengono riempiti di valori casuali tra 1 e 9 mentre nei campi qta vengono messi dei valori casuali tra 0 e 19.
Ogni elemento di questa struttura REC diventa il
campo x della lista a puntatori.
Al momento del caricamento, la funzione push ha l'ordine
di aggiornare il campo qta.
Cioè se i colli di un dato prodotto presenti nel magazzino sono meno di
9, la funzione li ordina e ne acquista altri 9.